“The representation perspective of deep learning is a powerful view that seems to answer why deep neural networks are so effective. Beyond that, I think there’s something extremely beautiful about it: why are neural networks effective? Because better ways of representing data can pop out of optimizing layered models.”
In machine learning, an embedding is a technique for converting data objects (such as words or images), potentially sparse, into low-dimensional vectors where each vector represents its corresponding object. This conversion process allows us to use these vectors to perform various tasks such as classification or regression. Embeddings are used widely in many areas of machine learning, including natural language processing, computer vision, and graph analysis.
Outside of textual data, for example, there are image embeddings, audio embeddings, and graph embeddings. For example, in image recognition tasks, CNNs learn image embeddings that capture visual patterns at different scales that can then be used for image classification, retrieval, or segmentation tasks. In audio, recall in the VALL-E paper that they used a neural audio codec model trained to compress and decompress digital audio files. The intermediate encoding is an audio embedding.
In graph analytics, node and edge features can be combined to create graph embeddings that encode information about the structure and connectivity of the graph. These embeddings can be useful for solving problems like link prediction, community detection, or clustering. See node2Vec and GraphSAGE.
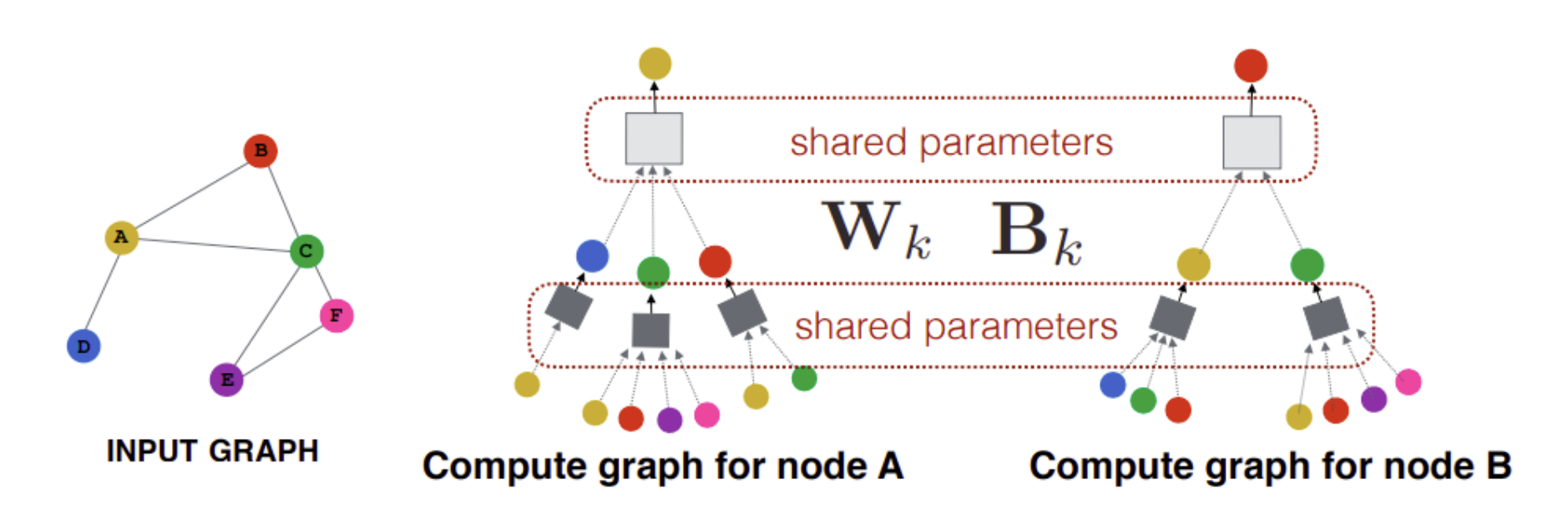
The “unrolled” equivalent neural network of GraphSAGE
In recommender systems, item embeddings reduce the dimensionality of the item catalog and allow for fast vector-search retrieval. New items can be cast into the item embedding space using similarity metrics based on item features before users have interacted with them at all. User embeddings alleviate the cold start problem in the same way.

A sample DNN architecture for learning movie embeddings from collaborative filtering data. From Google crash course on embeddings
Embeddings may finally allow neural network approaches to beat gradient boosted trees in tabular datasets:
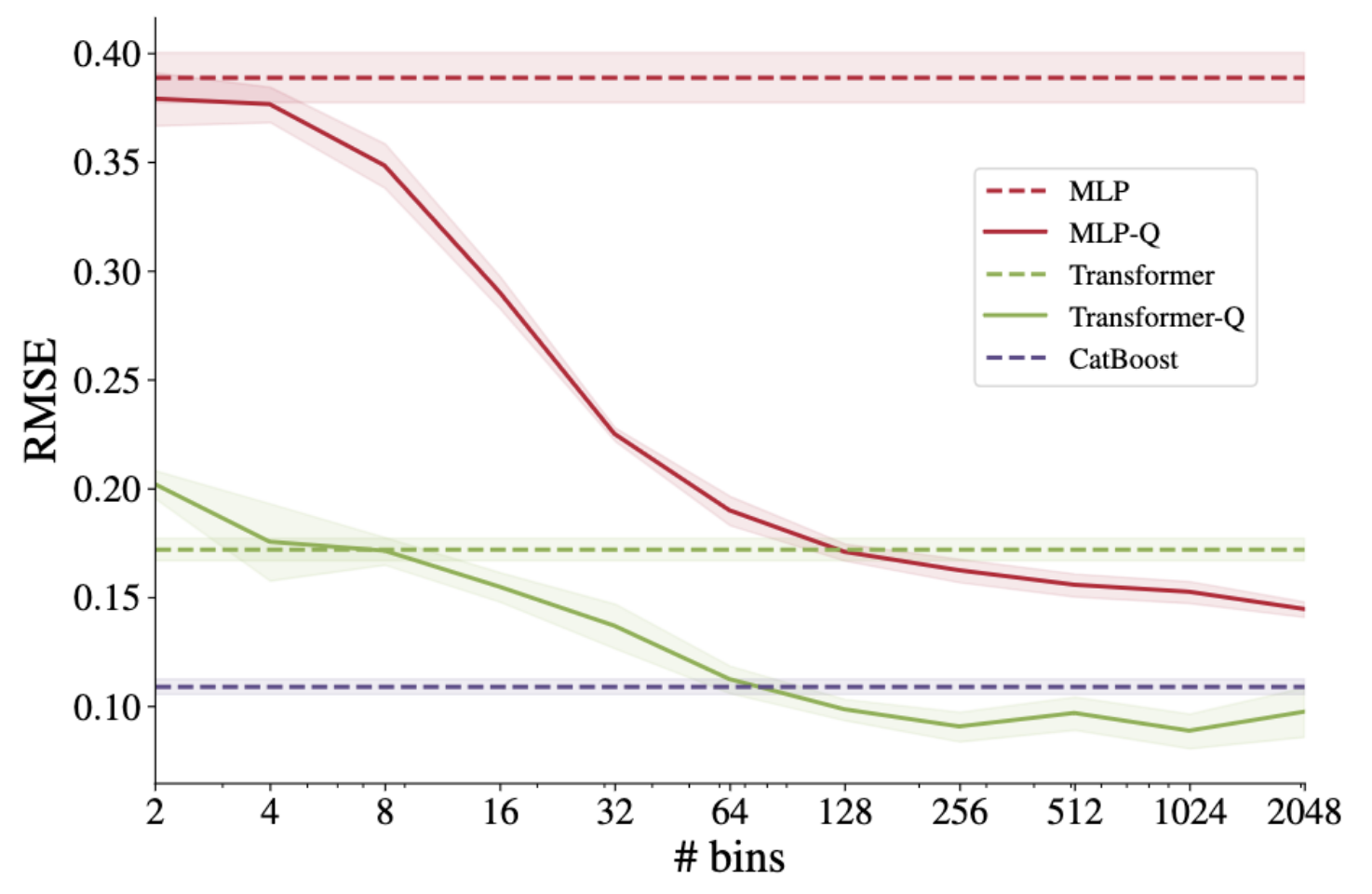
First, continuous features are expanded into quantile bins to create higher dimensional sparse features; then, learned embeddings of these features allow the neural network to outperform CatBoost in a synthetic GBDT-friendly task. https://arxiv.org/abs/2203.05556
Learning Embeddings
Much like the original word2vec or more modern language models, a surrogate task can be used to train embeddings: for sequences, predicting masked items (as in a MLM like BERT) or predicting next items (as in a causal language model like the GPT family); for tabular data, the surrogate task can be the prediction of one column based on the others; for image data, predicting the category of image is a common task. In a recommender task, predicting the rating a user will assign an item is a good task if such labels are available; predicting an implicit signal such as if they’ll choose an item from the selection or how long they’ll watch a video once they start it. Often, items selected can form a sequence and many of methods from language modelling can be used, eg. BERT4Rec.
The surrogate task doesn’t have to be the task you want the embeddings for; it should however depend on factors/features that are important for your downstream task. Eg. for the chairs dataset, if your surrogate model classifies the chair orientation, the resulting embeddings would do poorly to predict the chair style.
Furthermore, if you finetune your general purpose embeddings to a specific task, don’t expect them to still be useful for other tasks, see here as an example.
Vectors Properties of Embeddings
The famous example popularized in the word2vec paper (but first appearing in Linguistic Regularities in Continuous Space Word Representations)
King - Man + Woman = Queen
(though apparently, that expression requires tweaking). Why would the embeddings lie in a vector space? Frankly, the better question is: why wouldn’t they?
Since the underlying models are overwhelmingly linear and frequently shallow (word2vec has a single hidden layer; GloVe embeddings approximate the full word co-occurrence matrix by a low rank decomposition), we should expect embeddings to lie in a vector space where similar items will be close.
“Representing features as different directions may allow non-local generalization in models with linear transformations (such as the weights of neural nets), increasing their statistical efficiency relative to models which can only locally generalize.”
from Toy Models of Superposition1, they refer to a paper by Bengio and a blog post
This linearity will only be broken when there are interactions among features. In natural language, words can combine to form an altogether different meaning: eg. “wentelteefje”; “to fast”; or idioms such as “to break the ice”, “to let the cat out of the bag” or “to table an issue”. But these examples are a minority, and overwhelmingly most writing (on the internet) is simple and “additive”.
References
Representation Learning Without Labels, a well presented tutorial series at ICML 2020.
Notes
Footnotes
Toy Models of Superposition is an insightful writeup and I highly recommend reading!↩︎